实验课继续水一水!
XCTF逆向进阶区第二页也快做完了,实验课赶紧补一补wp吧
elrond32
拖入ida中查看main函数
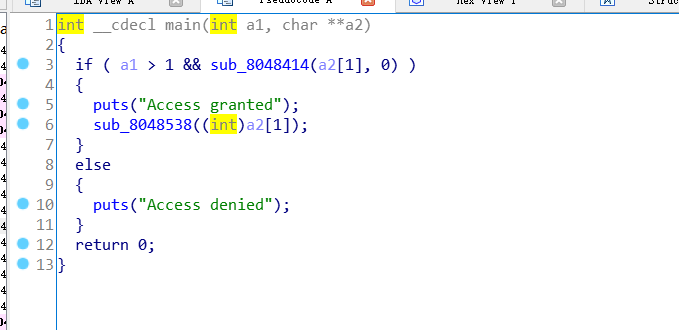
看见Access granted显然可知sub_8048538()函数是输出flag的函数,点开看看
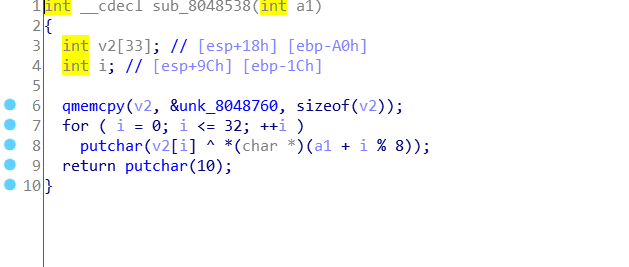
看代码发现我们需要得到数组a2的值,于是回到main函数,发现a2与sub_8048414()函数有关,点开看看

分析函数写出代码!
继续分析sub_8048538()函数,发现我们还需要知道v2数组的值,根据代码
qmemcpy(v2, &unk_8048760, sizeof(v2)); |
知道v2是从unk_8048760处复制了33个int
查看unk_8048760的值
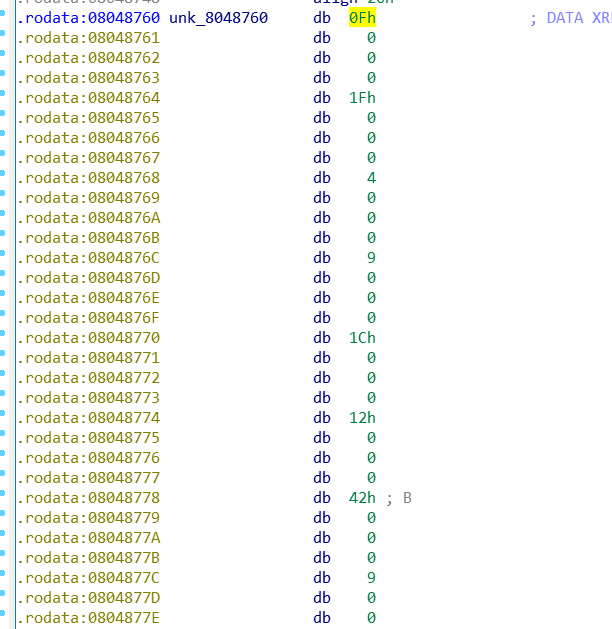
一个int占4个内存,所以剩下3个的内存用0填充,最后得出
data=[0x0F,0x1F,0x04,0x09,0x1C,0x12,0x42,0x09,0x0C,0x44,0x0D,0x07,0x09,0x06,0x2D,0x37,0x59,0x1E,0x00,0x59,0x0F,0x08,0x1C,0x23,0x36,0x07,0x55,0x02,0x0C,0x08,0x41,0x0A,0x14] |
编写代码得到flag
a='ie ndags r' |
tt3441810
这题根本不是逆向题
用01editor打开
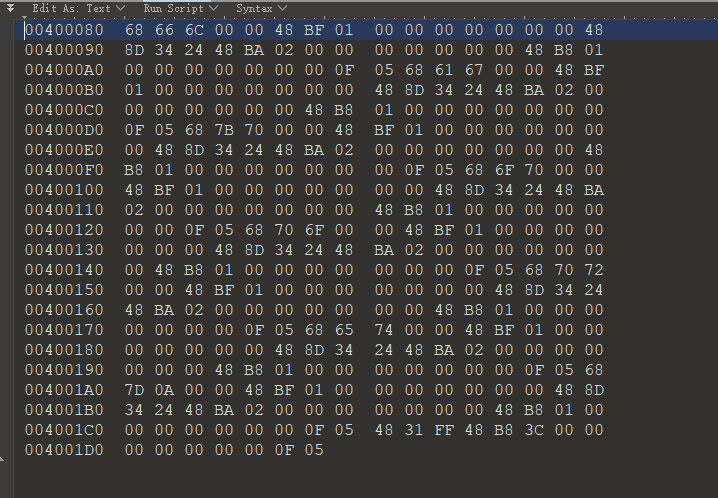
所以这道题的16进制转ASCII码又是一堆16进制,那我们把得到的16进制转ASCII
得到了很奇怪的输出,HH4$HH重复出现。
text=[0x68, 0x66, 0x6C, 0x00, 0x00, 0x48, 0xBF, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x48, |
re2-cpp-is-awesome
一道c++的题目,这道题我在给新生赛出逆向题目的时候写过类似样子的源码,所以比较的熟悉。
打开ida查看主函数

大部分都是些没有用的代码,第27行代码,是一个for循环,没有结束条件,每次增加sub_400D7A(&i),即1字节
_QWORD *__fastcall sub_400D7A(_QWORD *a1) |
for ( i = std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::begin(&v11); ; sub_400D7A(&i) ) |
通过对比sub_400B56(&i, &v13);和 sub_400B73(&i, &v13);函数,我们能够得到flag实际藏在if判断条件中
void __fastcall __noreturn sub_400B56(__int64 a1, __int64 a2, __int64 a3) |
__int64 __fastcall sub_400B73(__int64 a1, __int64 a2, __int64 a3) |
进入off_6020A0和dword_6020C0我们可以看到

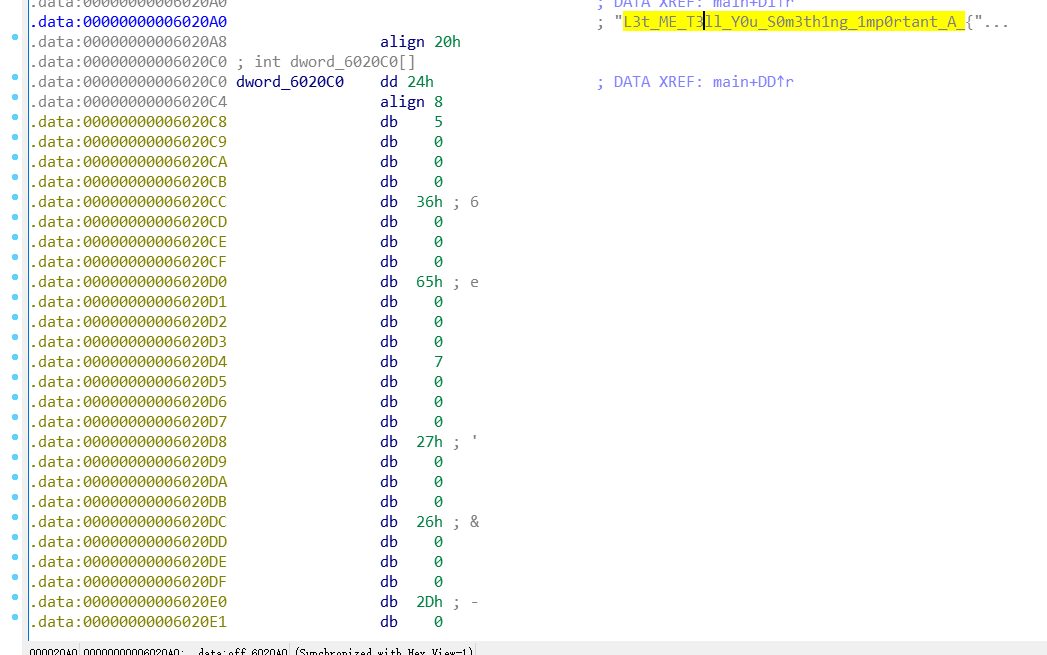
因此我们可以分析得出,通过v15/v14作为内部数组下标,循环获到的整数再作为外部数组的下标,获取到需要的字符串。
这里值得注意的一点是,algn 8表示两个数之间间隔8位,相当于在两个数之间插了7个0,也就相当于在头两个数之间还有一个’0’
写出脚本
S = 'L3t_ME_T3ll_Y0u_S0m3th1ng_1mp0rtant_A_{FL4G}_W0nt_b3_3X4ctly_th4t_345y_t0_c4ptur3_H0wev3r_1T_w1ll_b3_C00l_' |
re4-unvm-me
pyc在线pyc转
#!/usr/bin/env python |
16进制转md5,在线工具直接解
流浪者
根据字符串的查找,找到关键函数。
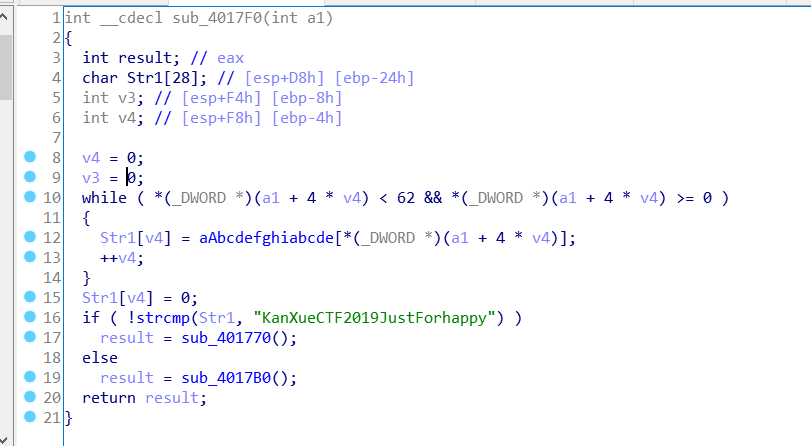
x交叉引用,找到引用了sub_4017f0的函数

分析函数
for ( i = 0; Str[i]; ++i ) |
写出解题脚本
tab='abcdefghiABCDEFGHIJKLMNjklmn0123456789opqrstuvwxyzOPQRSTUVWXYZ' |
666
没啥好解释的,拖入ida查看主函数,main函数中,用户输入保存到v5。然后调用encode(&v5,&s)函数。
在判断中,首先比较用户输入的长度是否等于key,也就是18。然后比较了s和enflag是否相等。s应该是刚刚调用encode函数后得到的。enflag的值为izwhroz""w"v.K".Ni
其中,key的值为18,enflag的值为izwhroz""w"v.K".Ni:
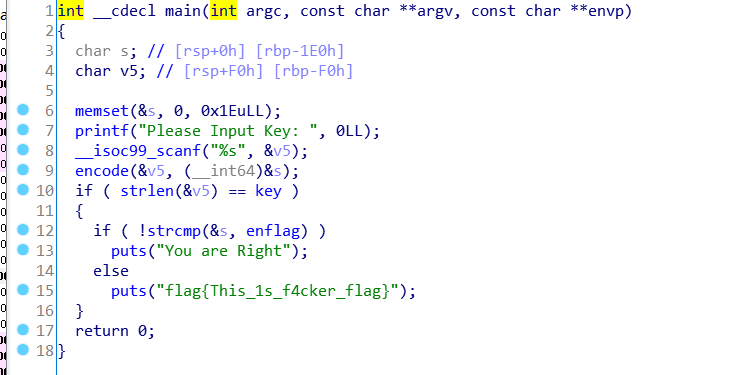
现在来看看encode函数。
a1也就是main函数里用户的输入v5,a2是main函数里的s,是最后要比较的字符串。
首先呢,检查了一下用户输入的长度,必须为key。
然后在一个for循环中,每次取用户输入的三个字符,分别做相关的异或运算,再分别赋值给a2的对应的位置。

对应写出脚本,这里分别用c和py分别写出相应代码。
|
enflag=[105, 122, 119, 104, 114, 111, 122, 34, 34, 119, |
ReverseMe-120
打开ida,首先查看一下程序逻辑
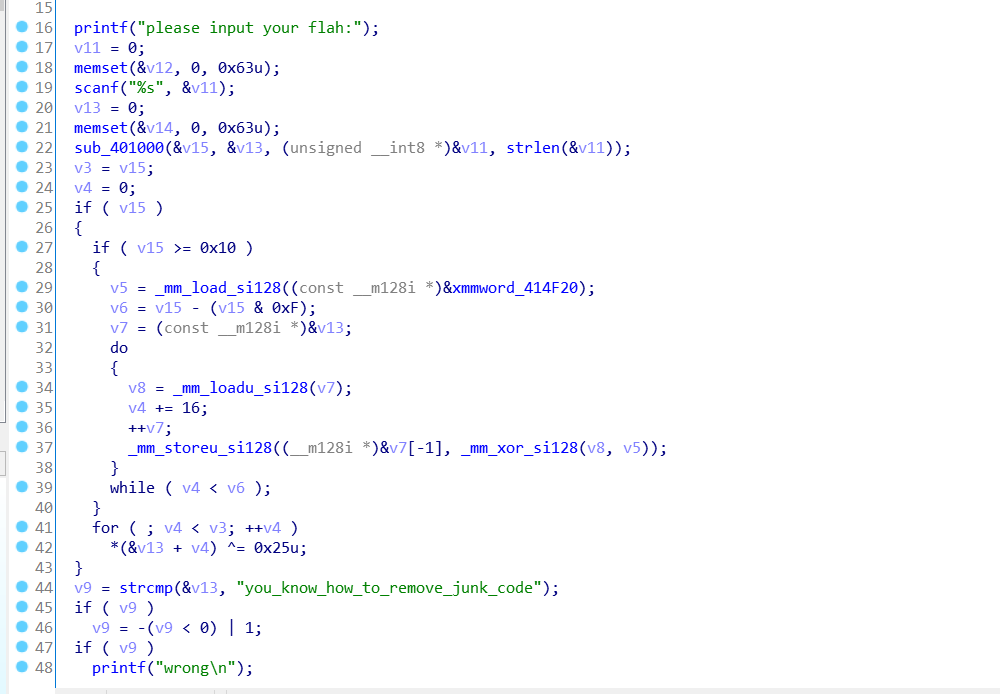
可以看到成功的条件是v9,而v9是v13与字符串”you_know_how_to_remove_junk_code“比较的结果。然后追一下v13的数据流,看看v13是怎么来的
可以看到v13的定义,以及一个关键函数sub_401000,为什么说是关键函数呢,因为函数的参数包含了刚定义的v13,以及你的输入v11。
我们跟进去看一看,注意我们想知道的是v13是怎么得到的,而v13作为第二个参数,在函数sub_401000里是a2,我们顺着a2去看。
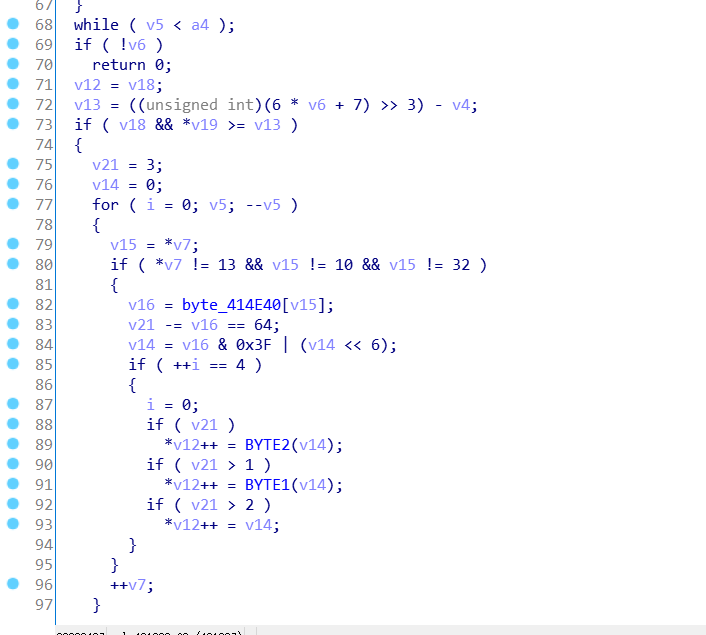
发现是base64加密。参考笔记:

写出解密脚本
import base64 |
EASYHOOK
IDA 打开,F5 分析 main 函数如下

大概分析可得,输入的 flag 长度应为 19,长度验证正确后会先调用 sub_401220 函数,该函数功能未知。然后通过 CreateFileA 和 WriteFile 将输入的 flag 写入到一个文件里面,双击 FileName 可知是写入到本地目录下的 Your_Input 文件里面。接着调用 sub_401240 函数,因为传入了 buffer 和NumberOfBytesWritten 的地址,结合紧跟着 sub_401240 后面的一个关键判断,所以很可能 sub_401240 就是对 flag 进行验证的关键函数了。
从上面分析得知,输入的长度为 19 的 flag 会被写入到文件里面。然而测试之后发现,写入到文件里面的 flag 发生了改变。回顾 main 函数的执行流程,可知对 flag 的修改要么发生在 sub_401220 函数里面,要么是WriteFile 函数出了问题。由于题目的名称给出了 hook 的提示信息,于是猜测在 sub_401220 里面 hook 了WriteFile 函数。直接 F5 分析 sub_401220 函数,报错。查看汇编代码得知猜测正确,分析如下:
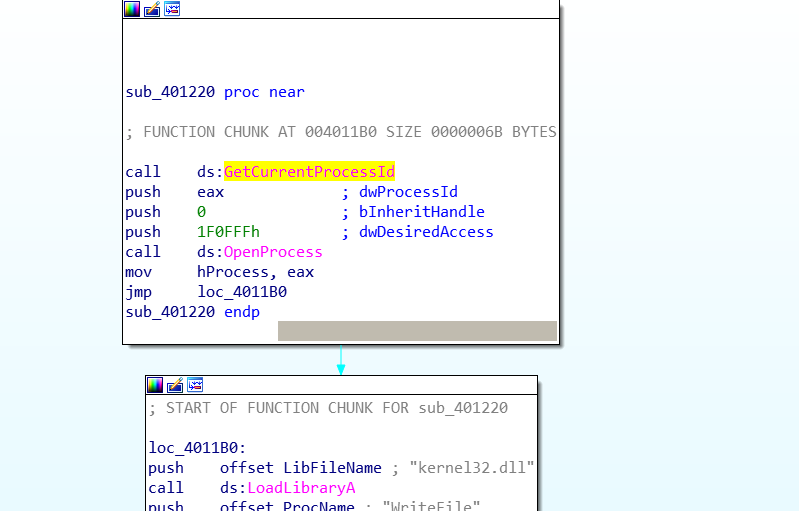
在 sub_401220 中获取进程句柄后跳转到loc_4011B0。
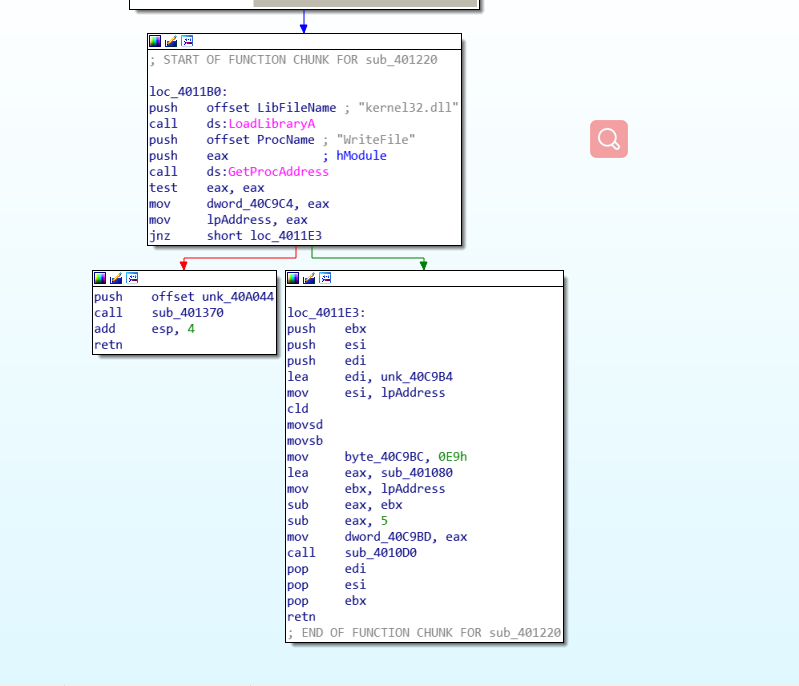
在 loc_401180 里面通过GetProcAddress 获取WriteFile 的地址,然后调用了sub_4010D0。注意红框框处的几个数据。
F5 查看 sub_4010D0,可知调用 VirtualProtectEx和 WriteProcessMemory 修改了 WriteFile 函数的起始 5 个字节。动态调试后发现修改为跳转到 sub_401080 的一条无条件跳转指令,从而实现了 hook WriteFile 的功能。
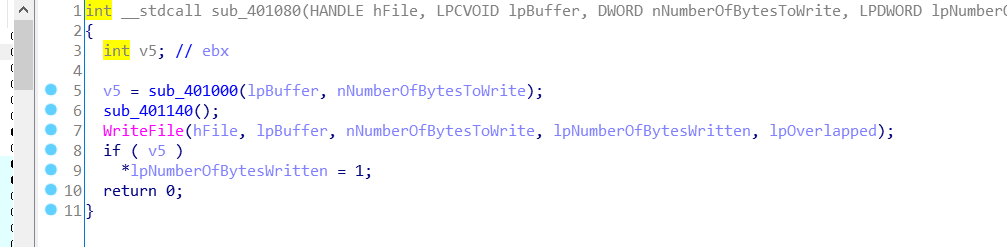
首先调用 sub_401000 函数,分析参数传递可知参数 lpBuffer 即是我们输入的 flag,那么很有可能就是在 sub_401000 里面对 flag 进行了修改。然后调用 sub_401140 函数,接着又一次调用了WriteFile 函数。我们知道虽然 WriteFile 被 hook 了,但最后确实是把 flag 写入到了文件里面,所以很有可能是在 sub_401140 里面对 WriteFIle 进行了 hook 还原。最后对 sub_401000 的返回值进行判断,如果非 0 则将NumberOfBytesWritten 置 1。
先分析sub_401140,证实了里面的 hook 还原操作。然后看一下 sub_401000,可知里面主要是两个循环处理:

这里就有一个很明显的字符串比较的意图了,结合上面的分析可知,我们输入的长度为 19 的 flag 经过第一个循环的处理之后,如果和 byte_40A030 指向的全局字符串相同,那么 sub_401000 返回 1。在 sub_401080 里面对sub_401000 的返回值进行判断,如果返回值为 1,则将NumberOfBytesWritten 置 1。然后在最外层的 main函数里面进行判断,如果NumberOfBytesWritten 为 1,则输出正确的提示信息。
所以,我们只需要将 byte_40A030 指向的字符串做一次 sub_401000 函数里面第一个循环处理的逆运算,就可以得到输入正确的 flag 了。
当然别忘了在 main 函数里面的 sub_401240 函数,我们刚开始时分析认为在 sub_401240 里面对输入的 flag 做了关键验证,但事实上真正的验证函数是 sub_401000,只要 sub_401000 验证正确即可。
贴上脚本分别用py和c分别实现
data=[ 0x61, 0x6A, 0x79, 0x67, 0x6B, 0x46, 0x6D, 0x2E, 0x7F, 0x5F, |
|
easyre-153
查看分析是32位elf文件,有壳
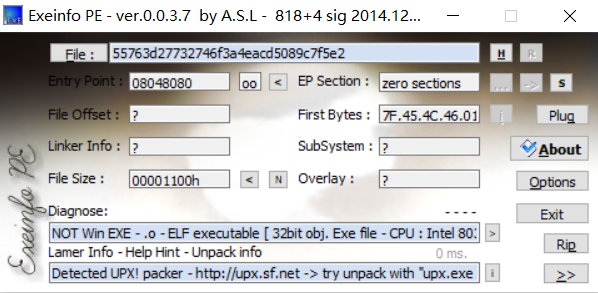
放到kali下进行脱壳
ida静态分析

pipe是完成两个进程之间通信的函数 1是写,0是读
fork是通过系统调用创建一个“子进程”的函数
fork的返回值,在子进程里面是0,在父进程里是子进程的进程id
所以我们可以很容易看出来 在子进程里面,由于v5==0,所以会输出刚刚我们看到的 OMG!!!! I forgot kid’s id 然后将69800876143568214356928753通过pipe传给父进程
完成这个任务后,子进程就会exit(0)
至于父进程,由于v5!=0,会跳过子进程刚刚执行的部分,直接读取子进程传给他的那一串数字 并且读取用户输入的v6
如果v6==v5 那么就会继续进行下面的操作
也就是说程序会创建一个管道,然后开启一个子进程进行进程间通信。子进程将 69800876143568214356928753 发送给父进程。父进程要求用户输入一个整数,并且等于子进程的 pid 。后面就会对发送过来的数据进行解码成 flag 输出来。
我们进入lol函数
再看流程图
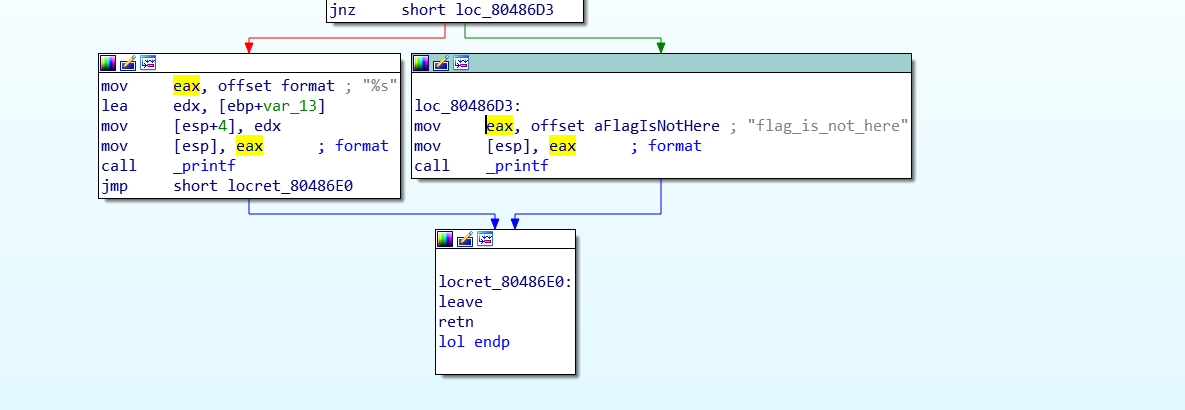
原来输出解码后的数据的那部分代码被作者改掉了,永远也不会执行。解码的操作也不复杂,直接用pthon脚本吧。
guo='69800876143568214356928753' |
IgniteMe
32位文件,无壳
拖入ida中查看,逻辑不太难,这里面我加了很多注释方便读懂程序。
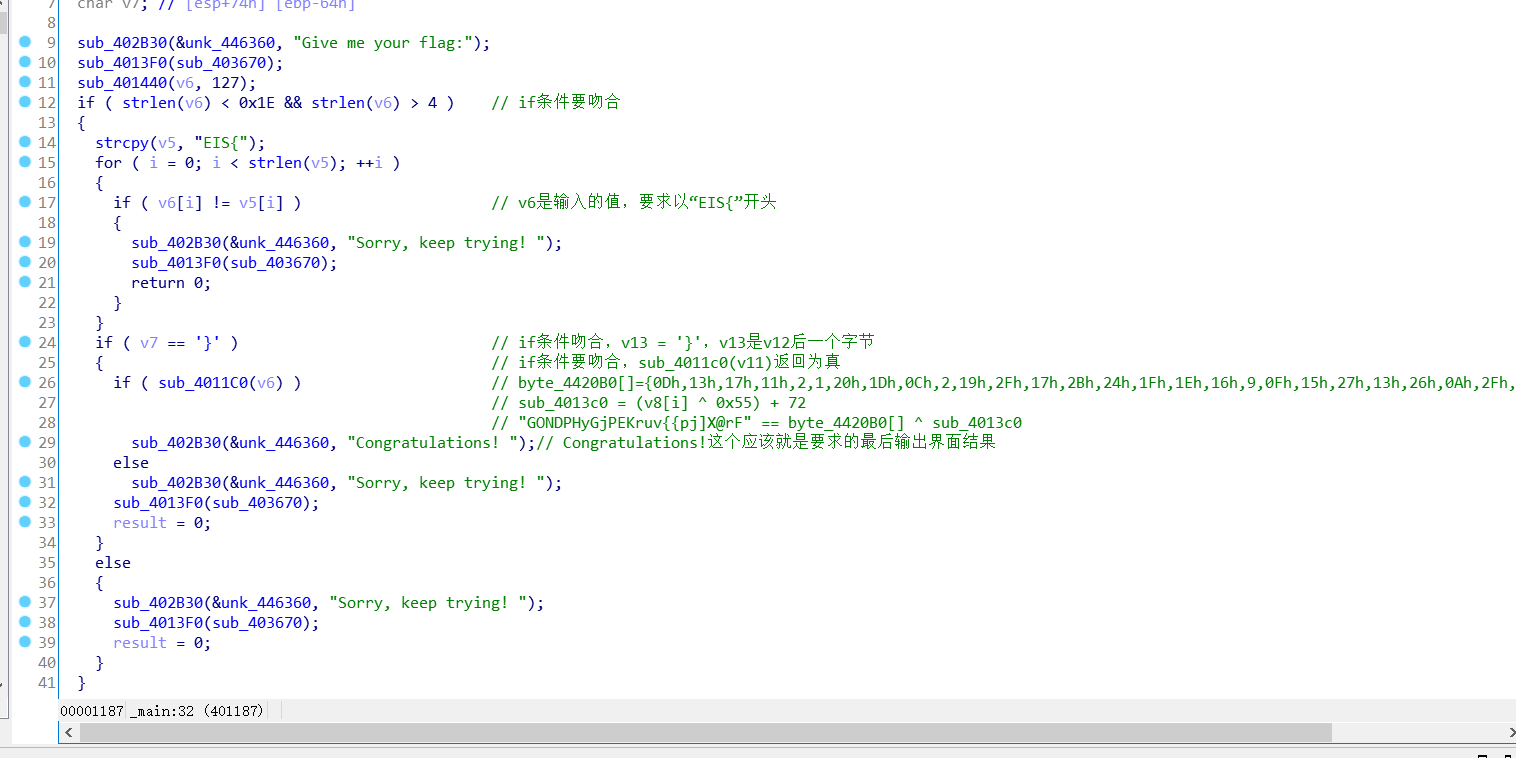
里面有一个很关键的函数sub_4011C0(),函数结构如下:


EXP
import string |
不过我个人还是喜欢写C语言的,这里也贴一下C语言代码
|
这里新学了一个ida小知识,数据可以用快捷键shift+E,在hex-view窗口里提取数据(这样就不用跟我一样一个一个输了)。
reverse-for-the-holy-grail-350
64位elf文件,拖入ida静态调试
查看主函数
int __cdecl main(int argc, const char **argv, const char **envp) |
加密还有 check 函数 全部都在stringMod 这个函数里面
__int64 __fastcall stringMod(__int64 *a1) |
stringMod函数校验过程一共分为三部分,第一部分中需要值得注意的是:v3是int型,除以一个数后小数部分会被去掉,所以3 * ((unsigned int)v3 / 3) == (_DWORD)v3成立的条件是v3是3的倍数,因此flag的第 3*n 个字符对应firstchar的六个字符
脚本
i = 666 |
EasyRE
不知道逆向题做到什么时候能有突破,不知道未来的方向在哪里,不知道我未来靠这个能做些什么,不知道自己何时能变得更强,眼下学了一年得逆向还在这做EasyRE,可笑可笑!
32位文件,无壳直接用IDA打开
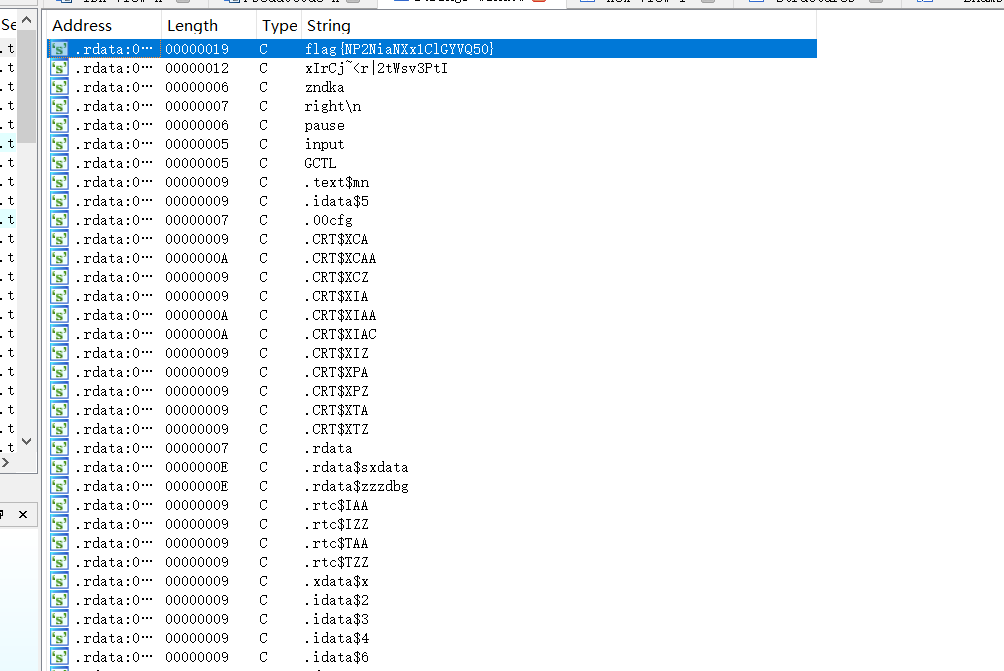
Shift+F12查看字符串窗口,发现flag,但是并不对。
注意到下面的right\n,是start函数,查看其伪代码。
signed int __usercall start@<eax>(int a1@<ebp>, int a2@<esi>) |
先拖进IDA 里看看吧!找到之前命令行中的提示字符串 input ,找到交叉引用该字符串的地方为函数sub_401080。(在查看strings windows的时候眼前一亮发现有个 flag{NP2NiaNXx1ClGYVQ50} ,但是输入以后发现并不是真正的flag…
F5查看函数sub_401080的伪代码。字符串 input 的地址为0x402150,结合代码,可以判断sub_401020函数为printf函数。再往下发现地址0x402158开始的字符串为%s,说明sub_401050应该是scanf函数,将用户输入保存到v7中。
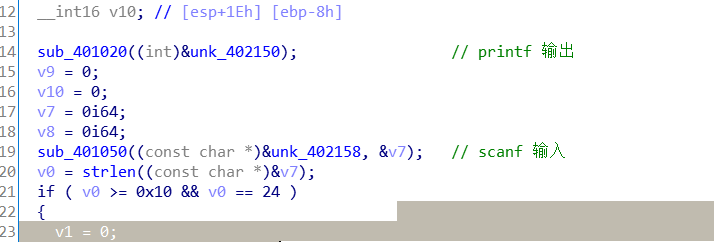
得到输入以后,对v7的长度进行检查,从代码中可知v7长度必须为24个字符。
接下来以 v8地址+7 位置处的字符赋值给v2,根据IDA的分析提示,v7的起始地址为ebp-24h(ebp-36), v8的起始地址为ebp-14h(ebp-20)。假设我输入的是abcdefghijklmnopqrstuvwx ,那么在栈中应该是下面的情况。也就是v2的初始值是用户输入的最后一个字符x。
| 高地址 | ebp-13 | x |
| | | ebp-14 | w |
| | | … | … |
| | | ebp-20 | q |
| | | … | … |
| ↓ | ebp-35 | b |
| 低地址 | ebp-36 | a |
每次循环中通过v1控制对用户输入字符串的遍历,将v2的值赋值给v3,然后v2地址自减1,也就是逆序取下一个字符。将v3保存的当前字符赋值给数组 byte_40336C[v1]。所以这个部分其实就是逆序提取用户输入,保存到数组byte_40336C的过程。

接下来对数组byte_40336C的每个值x进行 (x+1)^6的操作。

最后将数组byte_40336C,也就是一个字符串,与地址0x402124开始的字符串进行比较。如果相同,即strcmp返回值为0,则调用printf函数输出 right\n
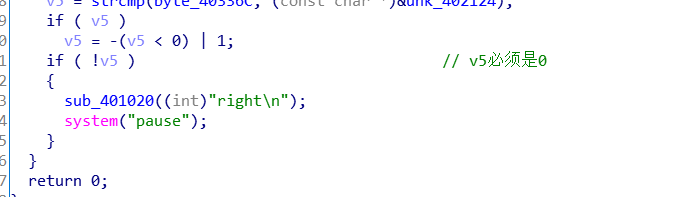
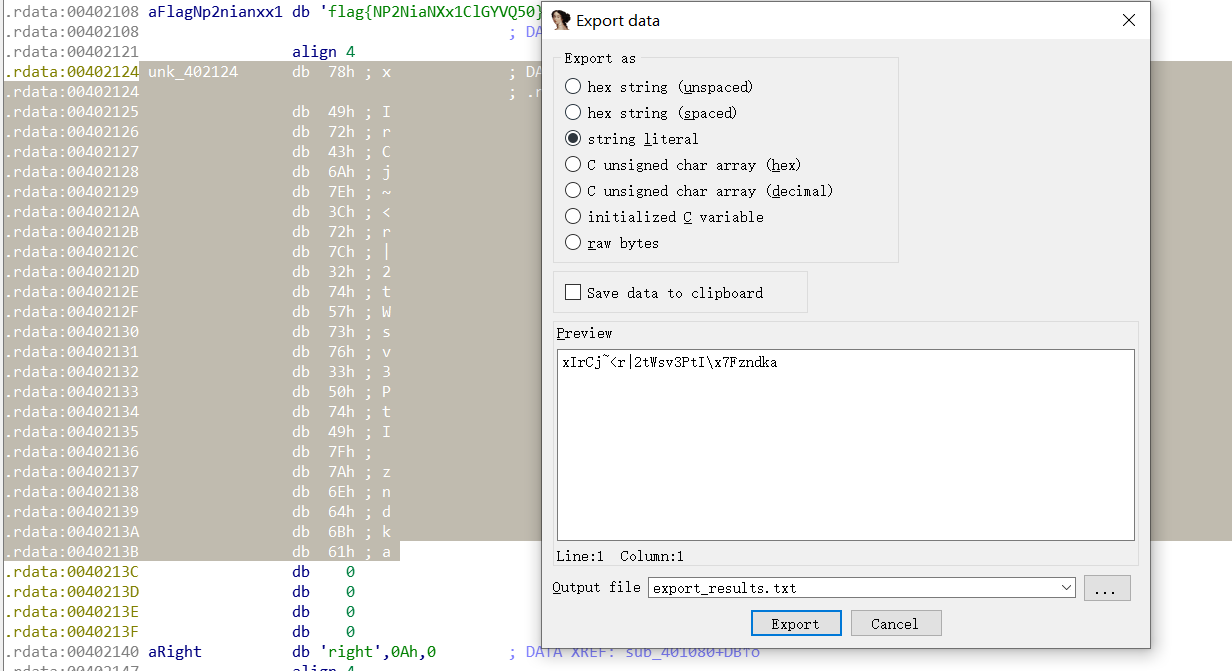
双击unk_402124,选中24个字符,按下 Shift + E 提取,选择 string literal ,得到的字符串为: xIrCj~<r|2tWsv3PtI\x7Fzndka 。
至此,整个程序的逻辑很清楚了:
- 在第1个部分中,读取用户输入
- 在第2部分中,判断用户输入的长度。逆序提取用户输入,保存到数组中(其实是个字符串)
- 在第3部分中,对数组每个值x进行 (x+1)^6的操作
- 在第4部分中,检查得到的数组(字符串)与
xIrCj~<r|2tWsv3PtI\x7Fzndka是否相等,相等则成功解决。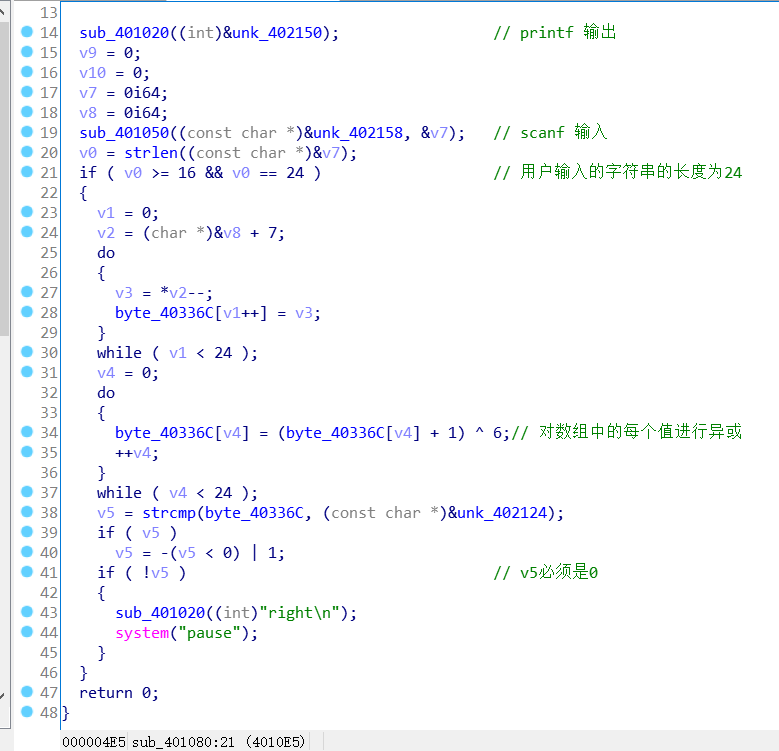
用python写脚本逆出正确的输入 flag{xNqU4otPq3ys9wkDsN}:
# user_input逆序,存到arr数组中 |
编写脚本的过程中有两个需要注意的:
1.异或运算的逆运算还是异或,比如:
x = 5 |
2.异或运算的优先级是低于减号的:
5^6 -1 # => 0 |